
Structuren
De structuur van een ecosysteem geeft de toestand van het systeem op een bepaald moment. Van belang hierbij is de ondeling verhouding van de verschillende populaties. Het gaat dan om de aantallen soorten en de aantallen individuen per soort. Het begrip 'biodiversiteit' wordt in dit kader veel genoemd. Zoals te zien is in het stuk over synecologie bestaat er een web aan relaties tussen de soorten in een ecosysteem. Als er veel soorten in een ecosysteem aanwezig zijn, dan kunnen er ook veel relaties ontstaan. Indien er verschuivingen in het milieu optreden, dan zullen bepaalde soorten in aantal veranderen en relaties veranderen (zie ook het deel over autecologie). Als er meer soorten aanwezig zijn, dan is een verschuiving mogelijk en blijft het ecosysteem in stand. Als er te weinig diversiteit aanwezig is, dan kan een verandering belangrijke relaties verbreken die niet meer kunnen worden opgevangen en stort het ecosysteem in. Dat is althans het idee achter de biodiversiteit. De realiteit is vele malen ingewikkelder. Het blijkt dat er binnen een groter ecosysteem een aantal kleinere deelsystemen of deelvoedselwebben te onderscheiden zijn, die slechts zijdelings met elkaar verbonden zijn. Als dit via wiskundige modellen op stabiliteit onderzocht wordt, dan blijkt dit opdelen de totale stabiliteit van het ecosysteem ten goede te komen. Dit wordt verklaard uit het verminderen van terugkoppelingen in het totale systeem.
Diversiteitsindexen
Om de diversiteit van soorten en aantallen in een ecosysteem te kunnen meten, zijn een aantal methoden ontwikkeld. Om te beginnen is het van belang een keus te maken tussen aantal organismen of volumina/biomassa van de organismen. Het verschil in massa of volume tussen organismen binnen een bepaalde groep kan enorm variëren. Als je naar de verdeling van vissen in een water kijkt, maakt het nogal een verschil of je naar de aantallen van bijvoorbeeld stekelbaars en snoek kijkt, of naar hun totale gewicht. In het algemeen wordt er toch met aantallen gewerkt, omdat volumina of biomassa slecht te schatten zijn en aantallen goed te tellen. Als compensatie kunnen van de aantallen eerste de logaritmen genomen worden. Hierdoor worden de grote en kleine aantallen naar elkaar toe getrokken. Vervolgens kunnen indexen van de diversiteit worden berekend, waarin zowel het aantal soorten als de aantallen per soort verwerkt worden. Er zijn veel van dergelijke diversiteitsindexen ontworpen, maar ze lijken veel op elkaar en in de praktijk blijkt het niet veel uit te maken welke je gebruikt. Het is wel van belang voor een goede vergelijking tussen metingen de aantallen individuen tussen verschillende berekeningen ongeveer gelijk te houden en ook het totaal aantal individuen in de metingen vrij groot te laten zijn. Liever duizenden dan honderden. Als voorbeeld volgen hier de twee bekendste en meest gebruikte indexen.
Index van Simpson
Simpson beschreef in 1949 een index waarbij trekkingskansen worden gesommeerd. Stel een gemeenschap dieren of planten met s als het aantal soorten en pi als p aantal individuen van soort i. Als je nu willekeurig telkens 2 individuen uit die gemeenschap trekt, heb je pi maal pi, ofwel pi2 kans dat beide individuen van dezelfde soort zijn. Hoe groter de kans dat beide individuen van dezelfde soort zijn, hoe hoger de index wordt. Om de index te berekenen tel je de kansen van alle soorten bij elkaar op. Je krijgt dan:
Index van Shannon
Deze index is oorspronkelijk afkomstig uit de signaalanalyse van de cybernetica (leer van de automatische regelings- en communicatiemechanismen) en geeft aan wat de onzekerheid is als je naar een stroom gegevens kijkt met s verschillende symbolen en pi als de fraktie p van symbool i. Hoe groter de onzekerheid over het volgende karakter in je stroom gegevens, hoe groter de index. Voor een levensgemeenschap betekent dat dus de onzekerheid die je hebt over welke soort het zal zijn, als je alle individuen van de gemeenschap een voor een langs zou zien komen. Hoe groter de onzekerheid, hoe hoger de index.
Voorbeeld
Om de verschillen te laten zien heb ik drie verdelingen genomen: twee extreme verdelingen en een meer natuurlijke verdeling. Telkens gaat het om 10 verschillende soorten verdeeld over 1000 individuen. De indexen rekenen beide met fracties p, dus wordt er gerekend met het aantal van iedere soort gedeeld door het totale aantal individuen.
| voorbeeld 1 | voorbeeld 2 | voorbeeld 3 | |
|---|---|---|---|
| soort 1 | 991 | 100 | 307 |
| soort 2 | 1 | 100 | 152 |
| soort 3 | 1 | 100 | 130 |
| soort 4 | 1 | 100 | 87 |
| soort 5 | 1 | 100 | 81 |
| soort 6 | 1 | 100 | 75 |
| soort 7 | 1 | 100 | 68 |
| soort 8 | 1 | 100 | 42 |
| soort 9 | 1 | 100 | 38 |
| soort 10 | 1 | 100 | 20 |
| totaal | 1000 | 1000 | 1000 |
Voorbeeld 1 geeft je dus het volgende sommetje voor de index van Simpson. Soort 1 heeft de fractie (991/1000)2 = 0,9912 = 0,982081. Soort 2 heeft de fractie (1/1000)2 = 0,0012 = 0,000001. En zo verder. Bij elkaar opgeteld wordt de index 0,9821 + 0,000001 + 0,000001 + .... = 0,98209.
Hetzelfde gaat op voor de index van Shannon. Ook hierbij wordt gekeken naar de fracties. Alleen wordt de fractie vermenigvuldigd met de natuurlijke logaritme van die zelfde fractie. Het sommetje wordt nu als volgt. Voor soort 1: 0,991 * ln(0,991) = 0,991 * -0,0090 = -0,00896. Doordat de waarde van de fractie kleiner is dan 1 wordt het logaritme negatief. De volgende soort geeft 0,001 * ln(0,001) = 0,001 * -6,908 = -0,0069. En zo verder. Opgeteld komt dat op -0,0711.Voor het berekenen van de Shannonindex moet dan nog de negatieve waarde worden genomen. Er staat immers een minteken voor het sommatieteken in de formule van de Shannonindex. Dit betekent dat de negatieve waarde positief wordt, zodat de index van Shannon voor het eerste voorbeeld uitkomt op 0,0711.
De zelfde sommetjes kan je maken voor de getallen uit voorbeeld 2 en 3. Je krijgt dan de volgende uitkomsten:
| voorbeeld 1 | voorbeeld 2 | voorbeeld 3 | |
|---|---|---|---|
| Simpson | 0,9821 | 0,1000 | 0,1622 |
| Shannon | 0,0711 | 2,3026 | 2,0429 |
De index van Simpson scoort hoog (vrijwel 1) indien een enkele soort overheerst. Als er slechts 1 soort aanwezig is, dan wordt de index altijd 1. Anders is de hoogste waarde:
Hierbij is s weer het aantal soorten (10) en q geeft het totaal aantal individuen in de berekening (1000). Even rekenen of het klopt. In de teller staan 2 stukken. Eerst: (q-s+1)2 geeft 1000-10+1 = 991 in het kwadraat, dus 991*991 = 982081. Hier tellen we 10-1 = 9 bij op, wordt 982081+9 = 982090. Dit delen we door q2 dus 1000*1000 = 1000000. Het antwoord is dan: 982090/1000000 = 0,98209. Klopt.
De laagste waarde is 1/s, dus 1/10 = 0,1. Daardoor loopt de index van hoge waarde met weinig diversiteit naar lage waarde met hoge diversiteit. Met diversiteit verstaan we hier een zo gelijkmatig mogelijke spreiding van de individuen over de soorten, dus geen dominante soorten aanwezig. Dat wordt gegeven in voorbeeld 2 en de uitkomst daarvan is inderdaad 1/s = 1/10 = 0,1. Aangezien we bij hoge diversiteit graag een hoge index willen zien, wordt de Simpsonindex vaak van 1 afgetrokken. Hierdoor lopen de waarden uiteen van 0 voor lage diversiteit tot 1-1/s voor hoge diversiteit, precies wat we willen.
Bij Shannon geeft de hoogste diversiteit wel de hoogste waarde en de laagste diversiteit de laagste indexwaarde aan. De grenzen zijn wat ingewikkelder en worden gevormd door ln(s) voor de hoogste waarde en de volgende formule voor de laagste waarde.
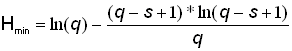
Ook dit even narekenen. De hoogste waarde wordt berekend door het natuurlijke logaritme te nemen van het aantal soorten, dus ln(10). Dit is 2,3026. Klopt. De laagste waarde is wat ingewikkelder en wordt opgebouwd uit 3 stukken. Eerst ln(q), dat is ln(1000)=6,90775. Dan (q - s + 1) x ln(q - s + 1) = (1000 - 10 + 1) x ln(1000 - 10 + 1) = 991 x ln(991) = 991 x 6,8987 = 6836,6261. Het uiteindelijke sommetje wordt dus 6,90775 - (6836,6261 / 1000) = 0,07115. Het verschil met 0,0711 komt door de afrondingen in de verschillende berekeningen. Het klopt.